15 Model-performance Measures
15.1 Introduction
In this chapter, we present measures that are useful for the evaluation of the overall performance of a (predictive) model.
As it was mentioned in Sections 2.1 and 2.5, in general, we can distinguish between the explanatory and predictive approaches to statistical modelling. Leo Breiman (2001b) indicates that validation of a model can be based on evaluation of goodness-of-fit (GoF) or on evaluation of predictive accuracy (which we will term goodness-of-predicton, GoP). In principle, GoF is mainly used for explanatory models, while GoP is applied for predictive models. In a nutshell, GoF pertains to the question: how well do the model’s predictions explain (fit) dependent-variable values of the observations used for developing the model? On the other hand, GoP is related to the question: how well does the model predict the value of the dependent variable for a new observation? For some measures, their interpretation in terms of GoF or GoP depends on whether they are computed by using training or testing data.
The measures may be applied for several purposes, including:
- model evaluation: we may want to know how good the model is, i.e., how reliable are the model’s predictions (how frequent and how large errors may we expect)?;
- model comparison: we may want to compare two or more models in order to choose between them;
- out-of-sample and out-of-time comparisons: we may want to check a model’s performance when applied to new data to evaluate if performance has not worsened.
Depending on the nature of the dependent variable (continuous, binary, categorical, count, etc.), different model-performance measures may be used. Moreover, the list of useful measures is growing as new applications emerge. In this chapter, we discuss only a selected set of measures, some of which are used in dataset-level exploration techniques introduced in subsequent chapters. We also limit ourselves to the two basic types of dependent variables continuous (including count) and categorical (including binary) considered in our book.
15.2 Intuition
Most model-performance measures are based on the comparison of the model’s predictions with the (known) values of the dependent variable in a dataset. For an ideal model, the predictions and the dependent-variable values should be equal. In practice, it is never the case, and we want to quantify the disagreement.
In principle, model-performance measures may be computed for the training dataset, i.e., the data used for developing the model. However, in that case there is a serious risk that the computed values will overestimate the quality of the model’s predictive performance. A more meaningful approach is to apply the measures to an independent testing dataset. Alternatively, a bias-correction strategy can be used when applying them to the training data. Toward this aim, various strategies have been proposed, such as cross-validation or bootstrapping (Kuhn and Johnson 2013; Harrell 2015; Steyerberg 2019). In what follows, we mainly consider the simple data-split strategy, i.e., we assume that the available data are split into a training set and a testing set. The model is created on the former, and the latter set is used to assess the model’s performance.
It is worth mentioning that there are two important aspects of prediction: calibration and discrimination (Harrell, Lee, and Mark 1996). Calibration refers to the extent of bias in predicted values, i.e., the mean difference between the predicted and true values. Discrimination refers to the ability of the predictions to distinguish between individual true values. For instance, consider a model to be used for weather forecasts in a region where, on average, it rains half the year. A simple model that predicts that every other day is rainy is well-calibrated because, on average, the resulting predicted risk of a rainy day in a year is 50%, which agrees with the actual situation. However, the model is not very much discriminative (for each calendar day, the probability of a correct prediction is 50%, the same as for a fair-coin toss) and, hence, not very useful.
Thus, in addition to overall measures of GoP, we may need separate measures for calibration and discrimination of a model. Note that, for the latter, we may want to weigh differently the situation when the prediction is, for instance, larger than the true value, as compared to the case when it is smaller. Depending on the decision on how to weigh different types of disagreement, we may need different measures.
In the best possible scenario, we can specify a single model-performance measure before the model is created and then optimize the model for this measure. But, in practice, a more common scenario is to use several performance measures, which are often selected after the model has been created.
15.3 Method
Assume that we have got a training dataset with \(n\) observations on \(p\) explanatory variables and on a dependent variable \(Y\). Let \(\underline{x}_i\) denote the (column) vector of values of the explanatory variables for the \(i\)-th observation, and \(y_i\) the corresponding value of the dependent variable. We will use \(\underline{X}=(x'_1,\ldots,x'_n)\) to denote the matrix of explanatory variables for all \(n\) observations, and \(\underline{y}=(y_1,\ldots,y_n)'\) to denote the (column) vector of the values of the dependent variable.
The training dataset is used to develop model \(f(\underline{\hat{\theta}}; \underline X)\), where \(\underline{\hat{\theta}}\) denotes the estimated values of the model’s coefficients. Note that could also use here the “penalized” estimates \(\underline{\tilde{\theta}}\) (see Section 2.5). Let \(\widehat{y}_i\) indicate the model’s prediction corresponding to \(y_i.\)
The model performance analysis is often based on an independent dataset called a testing set. In some cases, model-performance mesures are based on a leave-one-out approach. We will denote by \(\underline{X}_{-i}\) the matrix of explanatory variables when excluding the \(i\)-th observation and by \(f(\underline{\hat{\theta}}_{-i}; \underline{X}_{-i})\) the model developed for the reduced data. It is worth noting here that the leave-one-out model \(f(\underline{\hat{\theta}}_{-i}; \underline{X}_{-i})\) is different from the full-data model \(f(\underline{\hat{\theta}}; \underline X)\). But often they are close to each other and conclusions obtained from one can be transferred to the other. We will use \(\widehat{y}_{i(-i)}\) to denote the prediction for \(y_i\) obtained from model \(f(\underline{\hat{\theta}}_{-i}; \underline{X}_{-i})\).
In the subsequent sections, we present various model-performance measures. The measures are applied in essentially the same way if a training or a testing dataset is used. If there is any difference in the interpretation or properties of the measures between the two situations, we will explicitly mention them. Note that, in what follows, we will ignore in the notation the fact that we consider the estimated model \(f(\underline{\hat{\theta}}; \underline X)\) and we will use \(f()\) as a generic notation for it.
15.3.1 Continuous dependent variable
15.3.1.1 Goodness-of-fit
The most popular GoF measure for models for a continuous dependent variable is the mean squared-error, defined as
\[\begin{equation} MSE(f,\underline{X},\underline{y}) = \frac{1}{n} \sum_{i}^{n} (\widehat{y}_i - y_i)^2 = \frac{1}{n} \sum_{i}^{n} r_i^2, \tag{15.1} \end{equation}\]
where \(r_i\) is the residual for the \(i\)-th observation (see also Section 2.3). Thus, MSE can be seen as a sum of squared residuals. MSE is a convex differentiable function, which is important from an optimization point of view (see Section 2.5). As the measure weighs all differences equally, large residuals have got a high impact on MSE. Thus, the measure is sensitive to outliers. For a “perfect” model, which predicts (fits) all \(y_i\) exactly, \(MSE = 0\).
Note that MSE is constructed on a different scale from the dependent variable. Thus, a more interpretable variant of this measure is the root-mean-squared-error (RMSE), defined as
\[\begin{equation} RMSE(f, \underline{X}, \underline{y}) = \sqrt{MSE(f, \underline{X}, \underline{y})}. \tag{15.2} \end{equation}\]
A popular variant of RMSE is its normalized version, \(R^2\), defined as
\[\begin{equation} R^2(f, \underline{X}, \underline{y}) = 1 - \frac{MSE(f, \underline{X}, \underline{y})}{MSE(f_0, \underline{X},\underline{y})}. \tag{15.3} \end{equation}\]
In (15.3), \(f_0()\) denotes a “baseline” model. For instance, in the case of the classical linear regression, \(f_0()\) is the model that includes only the intercept, which implies the use of the mean value of \(Y\) as a prediction for all observations. \(R^2\) is normalized in the sense that the “perfectly” fitting model leads to \(R^2 = 1\), while \(R^2 = 0\) means that we are not doing better than the baseline model. In the context of the classical linear regression, \(R^2\) is the familiar coefficient of determination and can be interpreted as the fraction of the total variance of \(Y\) “explained” by model \(f()\).
Given sensitivity of MSE to outliers, sometimes the median absolute-deviation (MAD) is considered:
\[\begin{equation} MAD(f, \underline{X} ,\underline{y}) = median( |r_1|, ..., |r_n| ). \tag{15.4} \end{equation}\]
MAD is more robust to outliers than MSE. A disadvantage of MAD are its less favourable mathematical properties.
Section 15.4.1 illustrates the use of measures for the linear regression model and the random forest model for the apartment-prices data.
15.3.1.2 Goodness-of-prediction
Assume that a testing dataset is available. In that case, we can use model \(f()\), obtained by fitting the model to training data, to predict the values of the dependent variable observed in the testing dataset. Subsequently, we can compute MSE as in (15.1) to obtain the mean squared-prediction-error (MSPE) as a GoP measure (Kutner et al. 2005). By taking the square root of MSPE, we get the root-mean-squared-prediction-error (RMSPE).
In the absence of testing data, one of the most known GoP measures for models for a continuous dependent variable is the predicted sum-of-squares (PRESS), defined as
\[\begin{equation} PRESS(f,\underline{X},\underline{y}) = \sum_{i=1}^{n} (\widehat{y}_{i(-i)} - y_i)^2. \tag{15.5} \end{equation}\]
Thus, PRESS can be seen as a result of the application of the leave-one-out strategy to the evaluation of GoP of a model using the training data. Note that, for the classical linear regression model, there is no need to re-fit the model \(n\) times to compute PRESS (Kutner et al. 2005).
Based on PRESS, one can define the predictive squared-error \(PSE=PRESS/n\) and the standard deviation error in prediction \(SEP=\sqrt{PSE}=\sqrt{PRESS/n}\) (Todeschini 2010). Another measure gaining in popularity is
\[\begin{equation} Q^2(f,\underline{X},\underline{y}) = 1- \frac{ PRESS(f,\underline{X},\underline{y})}{\sum_{i=1}^{n} ({y}_{i} - \bar{y})^2}. \tag{15.6} \end{equation}\]
It is sometimes called the cross-validated \(R^2\) or the coefficient of prediction (Landram, Abdullat, and Shah 2005). It appears that \(Q^2 \leq R^2\), i.e., the expected accuracy of out-of-sample predictions measured by \(Q^2\) cannot exceed the accuracy of in-sample estimates (Landram, Abdullat, and Shah 2005). For a “perfect” predictive model, \(Q^2=1\). It is worth noting that, while \(R^2\) always increases if an explanatory variable is added to a model, \(Q^2\) decreases when “noisy” variables are added to the model (Todeschini 2010).
The aforementioned measures capture the overall predictive performance of a model. A measure aimed at evaluating discrimination is the concordance index (c-index) (Harrell, Lee, and Mark 1996; Brentnall and Cuzick 2018). It is computed by considering all pairs of observations and computing the fraction of the pairs in which the ordering of the predictions corresponds to the ordering of the true values (Brentnall and Cuzick 2018). The index assumes the value of 1 in case of perfect discrimination and 0.25 for random discrimination.
Calibration can be assessed by a scatter plot of the predicted values of \(Y\) in function of the true ones (Harrell, Lee, and Mark 1996; van Houwelingen, H.C. 2000; Steyerberg et al. 2010). The plot can be characterized by its intercept and slope. In case of perfect prediction, the plot should assume the form of a straight line with intercept 0 and slope 1. A deviation of the intercept from 0 indicates overall bias in predictions (“calibration-in-the-large”), while the value of the slope smaller than 1 suggests overfitting of the model (van Houwelingen, H.C. 2000; Steyerberg et al. 2010). The estimated values of the coefficients can be used to re-calibrate the model (van Houwelingen, H.C. 2000).
15.3.2 Binary dependent variable
To introduce model-performance measures, we, somewhat arbitrarily, label the two possible values of the dependent variable as “success” and “failure”. Of course, in a particular application, the meaning of the “success” outcome does not have to be positive nor optimistic; for a diagnostic test, “success” often means detection of disease. We also assume that model prediction \(\widehat{y}_i\) takes the form of the predicted probability of success.
15.3.2.1 Goodness-of-fit
If we assign the value of 1 to success and 0 to failure, it is possible to use MSE, RMSE, and MAD, as defined in Equations (15.1), (15.2), (15.4), respectively, as a GoF measure. In fact, the MSE obtained in that way is equivalent to the Brier score, which can be also expressed as \[ \sum_{i=1}^{n} \{y_i(1-\widehat{y}_i)^2+(1-y_i)(\widehat{y}_i)^2\}/n. \] Its minimum value is 0 for a “perfect” model and 0.25 for an “uninformative” model that yields the predicted probability of 0.5 for all observations. The Brier score is often also interpreted as an overall predictive-performance measure for models for a binary dependent variable because it captures both calibration and the concentration of the predictive distribution (Rufibach 2010).
One of the main issues related to the summary measures based on MSE is that they penalize too mildly for wrong predictions. In fact, the maximum penalty for an individual prediction is equal to 1 (if, for instance, the model yields zero probability for an actual success). To address this issue, the log-likelihood function based on the Bernoulli distribution (see also (2.8)) can be considered:
\[\begin{equation} l(f, \underline{X},\underline{y}) = \sum_{i=1}^{n} \{y_i \ln(\widehat{y}_i)+ (1-y_i)\ln(1-\widehat{y}_i)\}. \tag{15.7} \end{equation}\]
Note that, in the machine-learning world, function \(-l(f, \underline{X} ,\underline{y})/n\) is often considered (sometimes also with \(\ln\) replaced by \(\log_2\)) and termed “log-loss” or “cross-entropy”. The log-likelihood heavily “penalizes” the cases when the model-predicted probability of success \(\widehat{y}_i\) is high for an actual failure (\(y_i=0\)) and low for an actual success (\(y_i=1\)).
The log-likelihood (15.7) can be used to define \(R^2\)-like measures (for a review, see, for example, Allison (2014)). One of the variants most often used is the measure proposed by Nagelkerke (1991):
\[\begin{equation} R_{bin}^2(f, \underline{X}, \underline{y}) = \frac{1-\exp\left(\frac{2}{n}\{l(f_0, \underline{X},\underline{y})-l(f, \underline{X},\underline{y})\}\right)} {1-\exp\left(\frac{2}{n}l(f_0, \underline{X},\underline{y})\right)} . \tag{15.8} \end{equation}\]
It shares properties of the “classical” \(R^2\), defined in (15.3). In (15.8), \(f_0()\) denotes the model that includes only the intercept, which implies the use of the observed fraction of successes as the predicted probability of success. If we denote the fraction by \(\hat{p}\), then
\[ l(f_0, \underline{X},\underline{y}) = n \hat{p} \ln{\hat{p}} + n(1-\hat{p}) \ln{(1-\hat{p})}. \]
15.3.2.2 Goodness-of-prediction
In many situations, consequences of a prediction error depend on the form of the error. For this reason, performance measures based on the (estimated values of) probability of correct/wrong prediction are more often used.
To introduce some of those measures, we assume that, for each observation from the testing dataset, the predicted probability of success \(\widehat{y}_i\) is compared to a fixed cut-off threshold, \(C\) say. If the probability is larger than \(C\), then we assume that the model predicts success; otherwise, we assume that it predicts failure. As a result of such a procedure, the comparison of the observed and predicted values of the dependent variable for the \(n\) observations in a dataset can be summarized in a table similar to Table 15.1.
True value: success |
True value: failure |
Total | |
|---|---|---|---|
\(\widehat{y}_i \geq C\), predicted: success |
True Positive: \(TP_C\) | False Positive (Type I error): \(FP_C\) | \(P_C\) |
\(\widehat{y}_i < C\), predicted: failure |
False Negative (Type II error): \(FN_C\) | True Negative: \(TN_C\) | \(N_C\) |
| Total | \(S\) | \(F\) | \(n\) |
In the machine-learning world, Table 15.1 is often referred to as the “confusion table” or “confusion matrix”. In statistics, it is often called the “decision table”. The counts \(TP_C\) and \(TN_C\) on the diagonal of the table correspond to the cases when the predicted and observed value of the dependent variable \(Y\) coincide. \(FP_C\) is the number of cases in which failure is predicted as a success. These are false-positive, or Type I error, cases. On the other hand, \(FN_C\) is the count of false-negative, or Type II error, cases, in which success is predicted as failure. Marginally, there are \(P_C\) predicted successes and \(N_C\) predicted failures, with \(P_C+N_C=n\). In the testing dataset, there are \(S\) observed successes and \(F\) observed failures, with \(S+F=n\).
The effectiveness of such a test can be described by various measures. Let us present some of the most popular examples.
The simplest measure of model performance is accuracy, defined as
\[ ACC_C = \frac{TP_C+TN_C}{n}. \]
It is the fraction of correct predictions in the entire testing dataset. Accuracy is of interest if true positives and true negatives are more important than their false counterparts. However, accuracy may not be very informative when one of the binary categories is much more prevalent (so called unbalanced labels). For example, if the testing data contain 90% of successes, a model that would always predict a success would reach an accuracy of 0.9, although one could argue that this is not a very useful model.
There may be situations when false positives and/or false negatives may be of more concern. In that case, one might want to keep their number low. Hence, other measures, focused on the false results, might be of interest.
In the machine-learning world, two other measures are often considered: precision and recall. Precision is defined as
\[ Precision_C = \frac{TP_C}{TP_C+FP_C} = \frac{TP_C}{P_C}. \]
Precision is also referred to as the positive predictive value. It is the fraction of correct predictions among the predicted successes. Precision is high if the number of false positives is low. Thus, it is a useful measure when the penalty for committing the Type I error (false positive) is high. For instance, consider the use of a genetic test in cancer diagnostics, with a positive result of the test taken as an indication of an increased risk of developing a cancer. A false-positive result of a genetic test might mean that a person would have to unnecessarily cope with emotions and, possibly, medical procedures related to the fact of being evaluated as having a high risk of developing a cancer. We might want to avoid this situation more than the false-negative case. The latter would mean that the genetic test gives a negative result for a person that, actually, might be at an increased risk of developing a cancer. However, an increased risk does not mean that the person will develop cancer. And even so, we could hope that we could detect it in due time.
Recall is defined as
\[ Recall_C = \frac{TP_C}{TP_C+FN_C} = \frac{TP_C}{S}. \]
Recall is also referred to as sensitivity or the true-positive rate. It is the fraction of correct predictions among the true successes. Recall is high if the number of false negatives is low. Thus, it is a useful measure when the penalty for committing the Type II error (false negative) is high. For instance, consider the use of an algorithm that predicts whether a bank transaction is fraudulent. A false-negative result means that the algorithm accepts a fraudulent transaction as a legitimate one. Such a decision may have immediate and unpleasant consequences for the bank, because it may imply a non-recoverable loss of money. On the other hand, a false-positive result means that a legitimate transaction is considered as a fraudulent one and is blocked. However, upon further checking, the legitimate nature of the transaction can be confirmed with, perhaps, the annoyed client as the only consequence for the bank.
The harmonic mean of these two measures defines the F1 score:
\[ F1\ score_C = \frac{2}{\frac{1}{Precision_C} + \frac{1}{Recall_C}} = 2\cdot\frac{Precision_C \cdot Recall_C}{Precision_C + Recall_C}. \]
F1 score tends to give a low value if either precision or recall is low, and a high value if both precision and recall are high. For instance, if precision is 0, F1 score will also be 0 irrespectively of the value of recall. Thus, it is a useful measure if we have got to seek a balance between precision and recall.
In statistics, and especially in applications in medicine, the popular measures are sensitivity and specificity. Sensitivity is simply another name for recall. Specificity is defined as
\[ Specificity_C = \frac{TN_C}{TN_C + FP_C} = \frac{TN_C}{F}. \]
Specificity is also referred to as the true-negative rate. It is the fraction of correct predictions among the true failures. Specificity is high if the number of false positives is low. Thus, as precision, it is a useful measure when the penalty for committing the Type I error (false positive) is high.
The reason why sensitivity and specificity may be more often used outside the machine-learning world is related to the fact that their values do not depend on the proportion \(S/n\) (sometimes termed prevalence) of true successes. This means that, once estimated in a sample obtained from a population, they may be applied to other populations, in which the prevalence may be different. This is not true for precision, because one can write
\[ Precision_C = \frac{Sensitivity_C \cdot \frac{S}{n}}{Sensitivity_C \cdot \frac{S}{n}+Specificity_C \cdot \left(1-\frac{S}{n}\right)}. \]
All the measures depend on the choice of cut-off \(C\). To assess the form and the strength of dependence, a common approach is to construct the Receiver Operating Characteristic (ROC) curve. The curve plots \(Sensitivity_C\) in function of \(1-Specificity_C\) for all possible, ordered values of \(C\). Figure 15.2 presents the ROC curve for the random forest model for the Titanic dataset. Note that the curve indicates an inverse relationship between sensitivity and specificity: by increasing one measure, the other is decreased.
The ROC curve is very informative. For a model that predicts successes and failures at random, the corresponding curve will be equal to the diagonal line. On the other hand, for a model that yields perfect predictions, the ROC curve reduces to two intervals that connect points (0,0), (0,1), and (1,1).
Often, there is a need to summarize the ROC curve with one number, which can be used to compare models. A popular measure that is used toward this aim is the area under the curve (AUC). For a model that predicts successes and failures at random, AUC is the area under the diagonal line, i.e., it is equal to 0.5. For a model that yields perfect predictions, AUC is equal to 1. It appears that, in this case, AUC is equivalent to the c-index (see Section 15.3.1.2).
Another ROC-curve-based measure that is often used is the Gini coefficient \(G\). It is closely related to AUC; in fact, it can be calculated as \(G = 2 \times AUC - 1\). For a model that predicts successes and failures at random, \(G=0\); for a perfect-prediction model, \(G = 1\). Figure 15.2 illustrates the calculation of the Gini coefficient for the random forest model for the Titanic dataset (see Section 4.2.2).
A variant of ROC curve based on precision and recall is a called a precision-recall curve. Figure 15.3 the curve for the random forest model for the Titanic dataset.
The value of the Gini coefficient or, equivalently, of \(AUC-0.5\) allows a comparison of the model-based predictions with random guessing. A measure that explicitly compares a prediction model with a baseline (or null) model is the lift. Commonly, random guessing is considered as the baseline model. In that case,
\[ Lift_C = \frac{\frac{TP_C}{P_C}}{\frac{S}{n}} = n\frac{Precision_C}{S}. \]
Note that \(S/n\) can be seen as the estimated probability of a correct prediction of success for random guessing. On the other hand, \(TP_C/P_C\) is the estimated probability of a correct prediction of a success given that the model predicts a success. Hence, informally speaking, the lift indicates how many more (or less) times does the model do better in predicting success as compared to random guessing. As other measures, the lift depends on the choice of cut-off \(C\). The plot of the lift as a function of \(P_C\) is called the lift chart. Figure 15.3 presents the lift chart for the random forest model for the Titanic dataset.
Calibration of predictions can be assessed by a scatter plot of the predicted values of \(Y\) in function of the true ones. A complicating issue is a fact that the true values are only equal to 0 or 1. Therefore, smoothing techniques or grouping of observations is needed to obtain a meaningful plot (Steyerberg et al. 2010; Steyerberg 2019).
There are many more measures aimed at measuring the performance of a predictive model for a binary dependent variable. An overview can be found in, e.g., Berrar (2019).
15.3.3 Categorical dependent variable
To introduce model-performance measures for a categorical dependent variable, we assume that \(\underline{y}_i\) is now a vector of \(K\) elements. Each element \(y_{i}^k\) (\(k=1,\ldots,K\)) is a binary variable indicating whether the \(k\)-th category was observed for the \(i\)-th observation. We assume that, for each observation, only one category can be observed. Thus, all elements of \(\underline{y}_i\) are equal to 0 except one that is equal to 1. Furthermore, we assume that a model’s prediction takes the form of a vector, \(\underline{\widehat{y}}_i\) say, of the predicted probabilities for each of the \(K\) categories, with \({\widehat{y}}_i^k\) denoting the probability for the \(k\)-th category. The predicted category is the one with the highest predicted probability.
15.3.3.1 Goodness-of-fit
The log-likelihood function (15.7) can be adapted to the categorical dependent variable case as follows:
\[\begin{equation} l(f, \underline{X} ,\underline{y}) = \sum_{i=1}^{n}\sum_{k=1}^{K} y_{i}^k \ln({\widehat{y}}_i^k). \tag{15.9} \end{equation}\]
It is essentially the log-likelihood function based on a multinomial distribution. Based on the likelihood, an \(R^2\)-like measure can be defined, using an approach similar to the one used in (15.8) for construction of \(R_{bin}^2\) (Harrell 2015).
15.3.3.2 Goodness-of-prediction
It is possible to extend measures like accuracy, precision, etc., introduced in Section 15.3.2 for a binary dependent variable, to the case of a categorical one. Toward this end, first, a confusion table is created for each category \(k\), treating the category as “success” and all other categories as “failure”. Let us denote the counts in the table by \(TP_k\), \(FP_k\), \(TN_k\), and \(FN_k\). Based on the counts, we can compute the average accuracy across all classes as follows:
\[\begin{equation} \overline{ACC_C} = \frac{1}{K}\sum_{k=1}^K\frac{TP_{C,k}+TN_{C,k}}{n}. \tag{15.10} \end{equation}\]
Similarly, one could compute the average precision, average sensitivity, etc. In the machine-learning world, this approach is often termed “macro-averaging” (Sokolva and Lapalme 2009; Tsoumakas, Katakis, and Vlahavas 2010). The averages computed in that way treat all classes equally.
An alternative approach is to sum the appropriate counts from the confusion tables for all classes, and then form a measure based on the so-computed cumulative counts. For instance, for precision, this would lead to
\[\begin{equation} \overline{Precision_C}_{\mu} = \frac{\sum_{k=1}^K TP_{C,k}}{\sum_{k=1}^K (TP_{C,k}+FP_{C,k})}. \tag{15.11} \end{equation}\]
In the machine-learning world, this approach is often termed “micro-averaging” (Sokolva and Lapalme 2009; Tsoumakas, Katakis, and Vlahavas 2010), hence subscript \(\mu\) for “micro” in (15.11). Note that, for accuracy, this computation still leads to (15.10). The measures computed in that way favour classes with larger numbers of observations.
15.3.4 Count dependent variable
In case of counts, one could consider using MSE or any of the measures for a continuous dependent variable mentioned in Section 15.3.1.1. However, a particular feature of count dependent variables is that their variance depends on the mean value. Consequently, weighing all contributions to MSE equally, as in (15.1), is not appropriate, because the same residual value \(r_i\) indicates a larger discrepancy for a smaller count \(y_i\) than for a larger one. Therefore, a popular measure of performance of a predictive model for counts is Pearson’s statistic:
\[\begin{equation} \chi^2(f,\underline{X},\underline{y}) = \sum_{i=1}^{n} \frac{(\widehat{y}_i - y_i)^2}{\widehat{y}_i} = \sum_{i=1}^{n} \frac{r_i^2}{\widehat{y}_i}. \tag{15.12} \end{equation}\]
From (15.12) it is clear that, if the same residual is obtained for two different observed counts, it is assigned a larger weight for the count for which the predicted value is smaller.
Of course, there are more measures of model performance as well as types of model responses (e.g., censored data). A complete list, even if it could be created, would be beyond the scope of this book.
15.4 Example
15.4.1 Apartment prices
Let us consider the linear regression model apartments_lm (see Section 4.5.1) and the random forest model apartments_rf (see Section 4.5.2) for the apartment-prices data (see Section 4.4). Recall that, for these data, the dependent variable, the price per square meter, is continuous. Hence, we can use the performance measures presented in Section 15.3.1. In particular, we consider MSE and RMSE.
Figure 15.1 presents a box plot of the absolute values of residuals for the linear regression and random forest models, computed for the testing-data. The computed values of RMSE are also indicated in the plots. The values are very similar for both models; we have already noted that fact in Section 4.5.4.
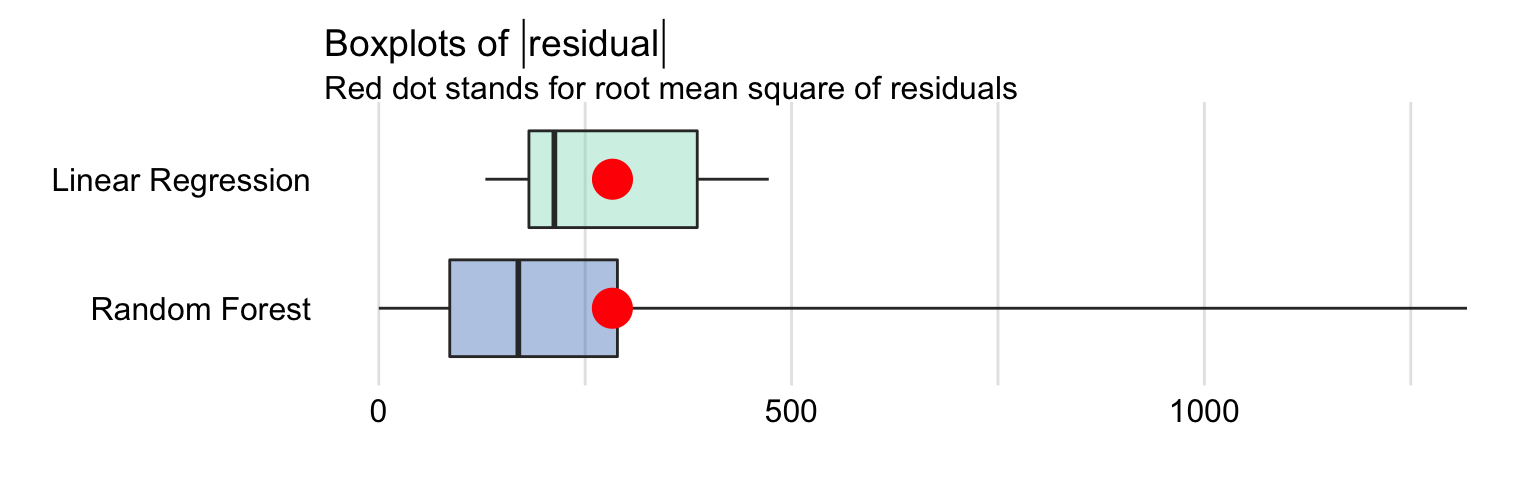
Figure 15.1: Box plot for the absolute values of residuals for the linear regression and random forest models for the apartment-prices data. The red dot indicates the RMSE.
In particular, MSE, RMSE, \(R^2\), and MAD values for the linear regression model are equal to 80137, 283.09, 0.901, and 212.7, respectively. For the random forest model, they are equal to 80137, 282.95, 0.901, and 169.1 respectively. The values of the measures suggest that the predicitve performance of the random forest model is slightly better. But is this difference relevant? It should be remembered that development of any random forest model includes a random component. This means that, when a random forest model is fitted to the same dataset several times, but using a different random-number-generation seed, the value of MSE or MAD for the fitted models will fluctuate. Thus, we should consider the values obtained for the linear regression and random forest models for the apartment-prices data as indicating a similar performance of the two models rather than a superiority of one of them.
15.4.2 Titanic data
Let us consider the random forest model titanic_rf (see Section 4.2.2) and the logistic regression model titanic_lmr (see Section 4.2.1) for the Titanic data (see Section 4.1). Recall that, for these data, the dependent variable is binary, with success defined as survival of the passenger.
First, we take a look at the random forest model. We will illustrate the “confusion table” by using threshold \(C\) equal to 0.5, i.e., we will classify passengers as “survivors” and “non-survivors” depending on whether their model-predicted probability of survival was larger than 50% or not, respectively. Table 15.2 presents the resulting table.
| Actual: survived | Actual: died | Total | |
|---|---|---|---|
| Predicted: survived | 454 | 60 | 514 |
| Predicted: died | 257 | 1436 | 1693 |
| Total | 711 | 1496 | 2207 |
Based on the table, we obtain the value of accuracy equal to (454 + 1436) / 2207 = 0.8564. The values of precision and recall (sensitivity) are equal to \(454 / 514 = 0.8833\) and \(454 / 711 = 0.6385\), respectively, with the resulting F1 score equal to 0.7412. Specificity is equal to \(1436 / 1496 = 0.9599\).
Figure 15.2 presents the ROC curve for the random forest model. AUC is equal to 0.8595, and the Gini coefficient is equal to 0.719.
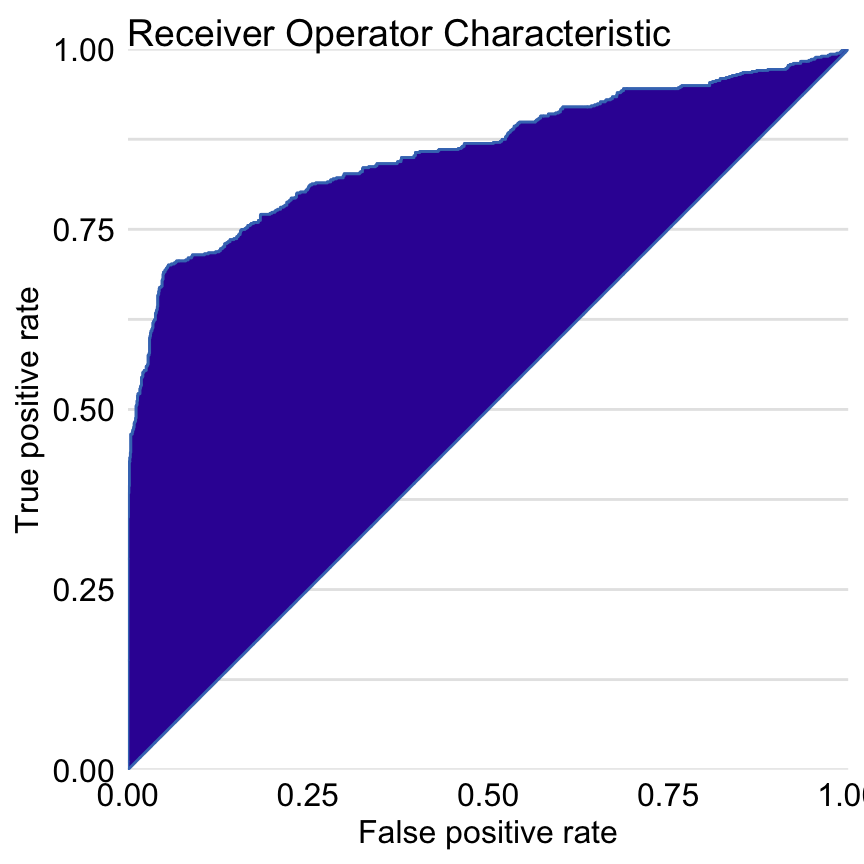
Figure 15.2: Receiver Operating Characteristic curve for the random forest model for the Titanic dataset. The Gini coefficient can be calculated as 2\(\times\) area between the ROC curve and the diagonal (this area is highlighted). The AUC coefficient is defined as an area under the ROC curve.
Figure 15.3 presents the precision-recall curve (left-hand-side panel) and lift chart (right-hand-side panel) for the random forest model.
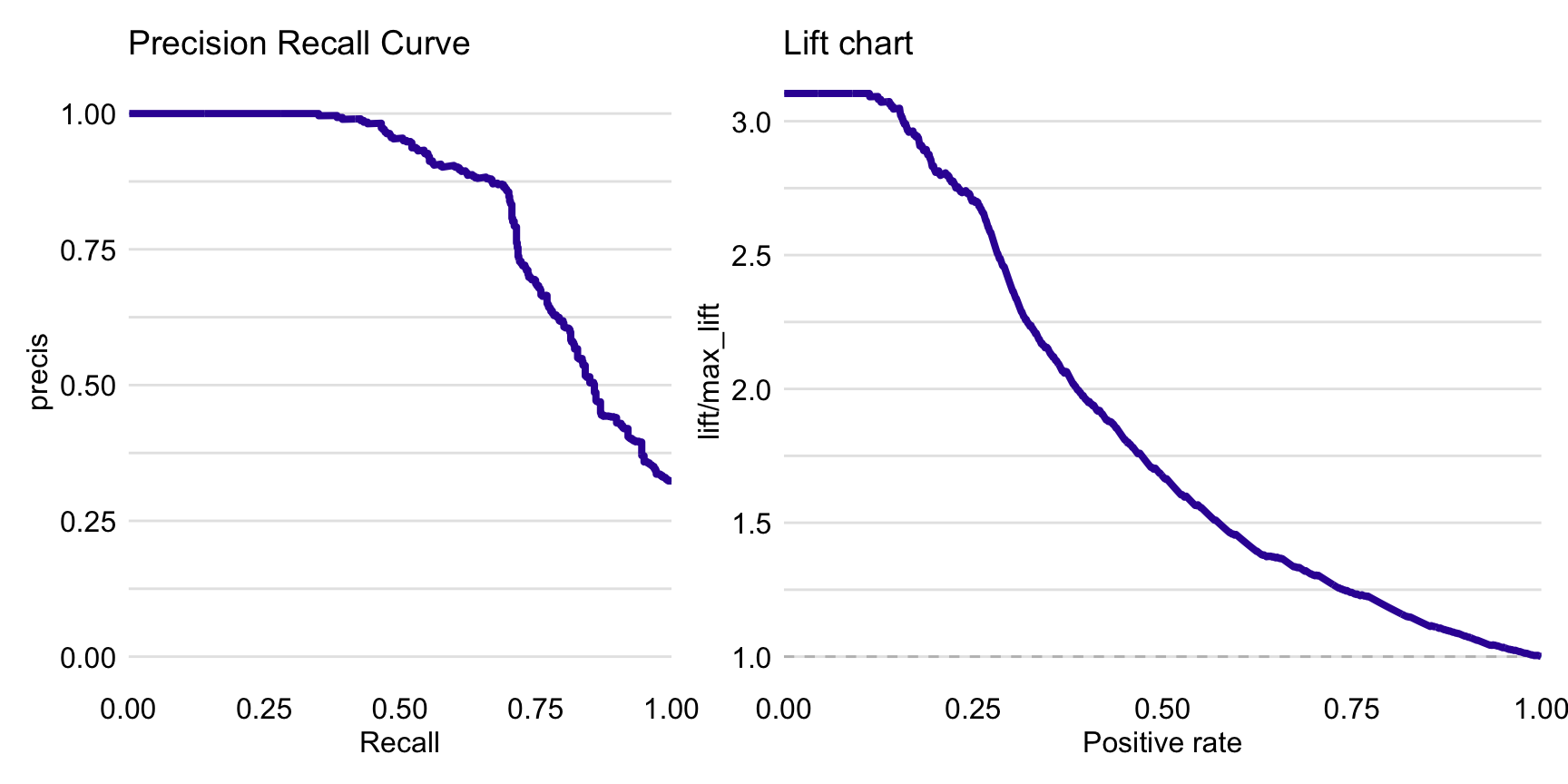
Figure 15.3: Precision-recall curve (left panel) and lift chart (right panel) for the random forest model for the Titanic dataset.
Table 15.3 presents the confusion table for the logistic regression model for threshold \(C\) equal to 0.5. The resulting values of accuracy, precision, recall (sensitivity), F1 score, and specificity are equal to 0.8043, 0.7522, 0.5851, 0.6582, and 0.9084. The values are smaller than for the random forest model, suggesting a better performance of the latter.
| Actual: survived | Actual: died | Total | |
|---|---|---|---|
| Predicted: survived | 416 | 137 | 653 |
| Predicted: died | 295 | 1359 | 1654 |
| Total | 711 | 1496 | 2207 |
Left-hand-side panel in Figure 15.4 presents ROC curves for both the logistic regression and the random forest model. The curve for the random forest model lies above the one for the logistic regression model for the majority of the cut-offs \(C\), except for the very high values of the cut-off \(C\). AUC for the logistic regression model is equal to 0.8174 and is smaller than for the random forest model. Right-hand-side panel in Figure 15.4 presents lift charts for both models. Also in this case the curve for the random forest suggests a better performance than for the logistic regression model, except for the very high values of cut-off \(C\).
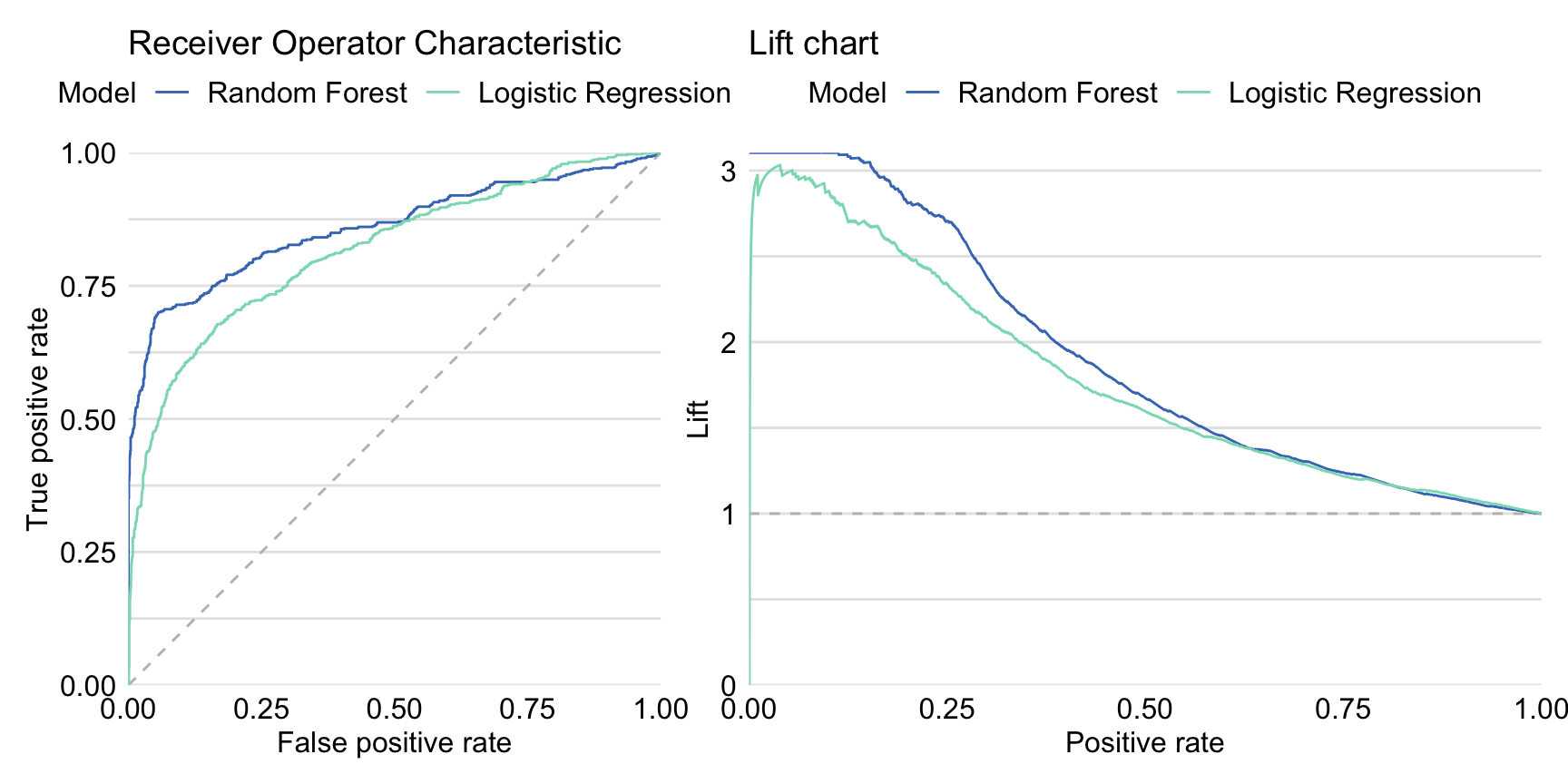
Figure 15.4: Receiver Operating Characteristic curves (left panel) and lift charts (right panel) for the random forest and logistic regression models for the Titanic dataset.
15.5 Pros and cons
All model-performance measures presented in this chapter are subject to some limitations. For that reason, many measures are available, as the limitations of a particular measure were addressed by developing an alternative one. For instance, RMSE is frequently used and reported for linear regression models. However, as it is sensitive to outliers, MAD has been proposed as an alternative. In case of predictive models for a binary dependent variable, measures like accuracy, F1 score, sensitivity, and specificity are often considered, depending on the consequences of correct/incorrect predictions in a particular application. However, the value of those measures depends on the cut-off value used for creating predictions. For this reason, ROC curve and AUC have been developed and have become very popular. They are not easily extended to the case of a categorical dependent variable, though.
Given the advantages and disadvantages of various measures and the fact that each may reflect a different aspect of the predictive performance of a model, it is customary to report and compare several of them when evaluating a model’s performance.
15.6 Code snippets for R
In this section, we present model-performance measures as implemented in the DALEX package for R. The package covers the most often used measures and methods presented in this chapter. More advanced measures of performance are available in the auditor package for R (Gosiewska and Biecek 2018). Note that there are also other R packages that offer similar functionality. These include, for instance, packages mlr (Bischl et al. 2016), caret (Kuhn 2008), tidymodels (Max and Wickham 2018), and ROCR (Sing et al. 2005).
For illustration purposes, we use the random forest model titanic_rf (see Section 4.2.2) and the logistic regression model titanic_lmr (see Section 4.2.1) for the Titanic data (see Section 4.1). Consequently, the DALEX functions are applied in the context of a binary classification problem. However, the same functions can be used for, for instance, linear regression models.
To illustrate the use of the functions, we first retrieve the titanic_lmr and titanic_rf model-objects via the archivist hooks, as listed in Section 4.2.7. We also retrieve the version of the titanic data with imputed missing values.
titanic_imputed <- archivist::aread("pbiecek/models/27e5c")
titanic_lmr <- archivist::aread("pbiecek/models/58b24")
titanic_rf <- archivist::aread("pbiecek/models/4e0fc")Then we construct the explainers for the models by using function explain() from the DALEX package (see Section 4.2.6). We also load the rms and randomForest packages, as the models were fitted by using functions from those packages and it is important to have the corresponding predict() functions available.
library("rms")
library("DALEX")
explain_lmr <- explain(model = titanic_lmr,
data = titanic_imputed[, -9],
y = titanic_imputed$survived == "yes",
type = "classification",
label = "Logistic Regression")
library("randomForest")
explain_rf <- explain(model = titanic_rf,
data = titanic_imputed[, -9],
y = titanic_imputed$survived == "yes",
label = "Random Forest")Function model_performance() calculates, by default, a set of selected model-performance measures. These include MSE, RMSE, \(R^2\), and MAD for linear regression models, and recall, precision, F1, accuracy, and AUC for models for a binary dependent variable. The function includes the cutoff argument that allows specifying the cut-off value for the measures that require it, i.e., recall, precision, F1 score, and accuracy. By default, the cut-off value is set at 0.5. Note that, by default, all measures are computed for the data that are extracted from the explainer object; these can be training or testing data.
## Measures for: classification
## recall : 0.6385373
## precision : 0.8832685
## f1 : 0.7412245
## accuracy : 0.8563661
## auc : 0.8595467
##
## Residuals:
## 0% 10% 20% 30% 40% 50% 60% 70%
## -0.8920 -0.1140 -0.0240 -0.0080 -0.0040 0.0000 0.0000 0.0100
## 80% 90% 100%
## 0.1400 0.5892 1.0000## Measures for: classification
## recall : 0.5850914
## precision : 0.7522604
## f1 : 0.6582278
## accuracy : 0.8042592
## auc : 0.81741
##
## Residuals:
## 0% 10% 20% 30% 40%
## -0.98457244 -0.31904861 -0.23408037 -0.20311483 -0.15200813
## 50% 60% 70% 80% 90%
## -0.10318060 -0.06933478 0.05858024 0.29306442 0.73666519
## 100%
## 0.97151255Application of the DALEX::model_performance() function returns an object of class “model_performance”, which includes estimated values of several model-performance measures, as well as a data frame containing the observed and predicted values of the dependent variable together with their difference, i.e., residuals. An ROC curve or lift chart can be constructed by applying the generic plot() function to the object. The type of the required plot is indicated by using argument geom. In particular, the argument allows values geom = "lift" for lift charts, geom = "roc" for ROC curves, geom = "histogram" for histograms of residuals, and geom = "boxplot" for box-and-whisker plots of residuals. The plot() function returns a ggplot2 object. It is possible to apply the function to more than one object. In that case, the plots for the models corresponding to each object are combined in one graph. In the code below, we create two ggplot2 objects: one for a graph containing precision-recall curves for both models, and one for a histogram of residuals. Subsequently, we use the patchwork package to combine the graphs in one display.
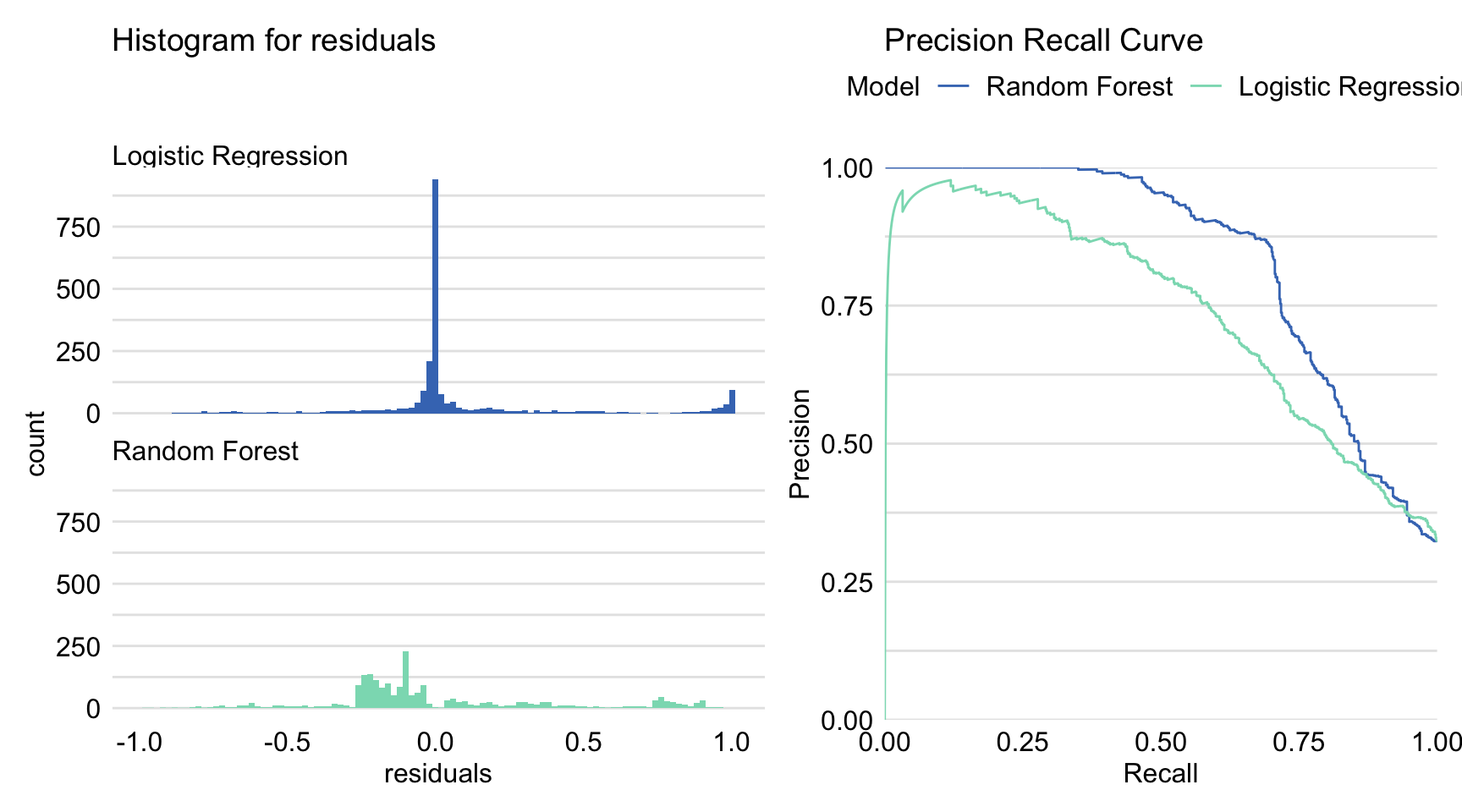
Figure 15.5: Precision-recall curves and histograms for residuals obtained by the generic plot() function in R for the logistic regression model titanic_lmr and the random forest model titanic_rf for the Titanic dataset.
The resulting graph is shown in Figure 15.5. Combined with the plot of ROC curves and the lift charts presented in both panels of Figure 15.4, it provides additional insight into the comparison of performance of the two models.
15.7 Code snippets for Python
In this section, we use the dalex library for Python. A collection of numerous metrics and performance charts is also available in the popular sklearn.metrics library.
For illustration purposes, we use the titanic_rf random forest model for the Titanic data developed in Section 4.3.2. Recall that the model is developed to predict the probability of survival for passengers of Titanic.
In the first step, we create an explainer-object that will provide a uniform interface for the predictive model. We use the Explainer() constructor for this purpose.
To calculate selected measures of the overall performance, we use the model_performance() method. In the syntax below, we apply the model_type argument to indicate that we deal with a classification problem, and the cutoff argument to specify the cutoff value equal to 0.5. It is worth noting that we get different results than in R. In both cases, the models may differ slightly in implementation and are also trained with a different random seed.

The resulting object can be visualised in many different ways. The code below constructs an ROC curve with AUC measure. Figure 15.6 presents the created plot.
import plotly.express as px
from sklearn.metrics import roc_curve, auc
y_score = titanic_rf_exp.predict(X)
fpr, tpr, thresholds = roc_curve(y, y_score)
fig = px.area(x=fpr, y=tpr,
title=f'ROC Curve (AUC={auc(fpr, tpr):.4f})',
labels=dict(x='False Positive Rate', y='True Positive Rate'),
width=700, height=500)
fig.add_shape(
type='line', line=dict(dash='dash'),
x0=0, x1=1, y0=0, y1=1)
fig.update_yaxes(scaleanchor="x", scaleratio=1)
fig.update_xaxes(constrain='domain')
fig.show()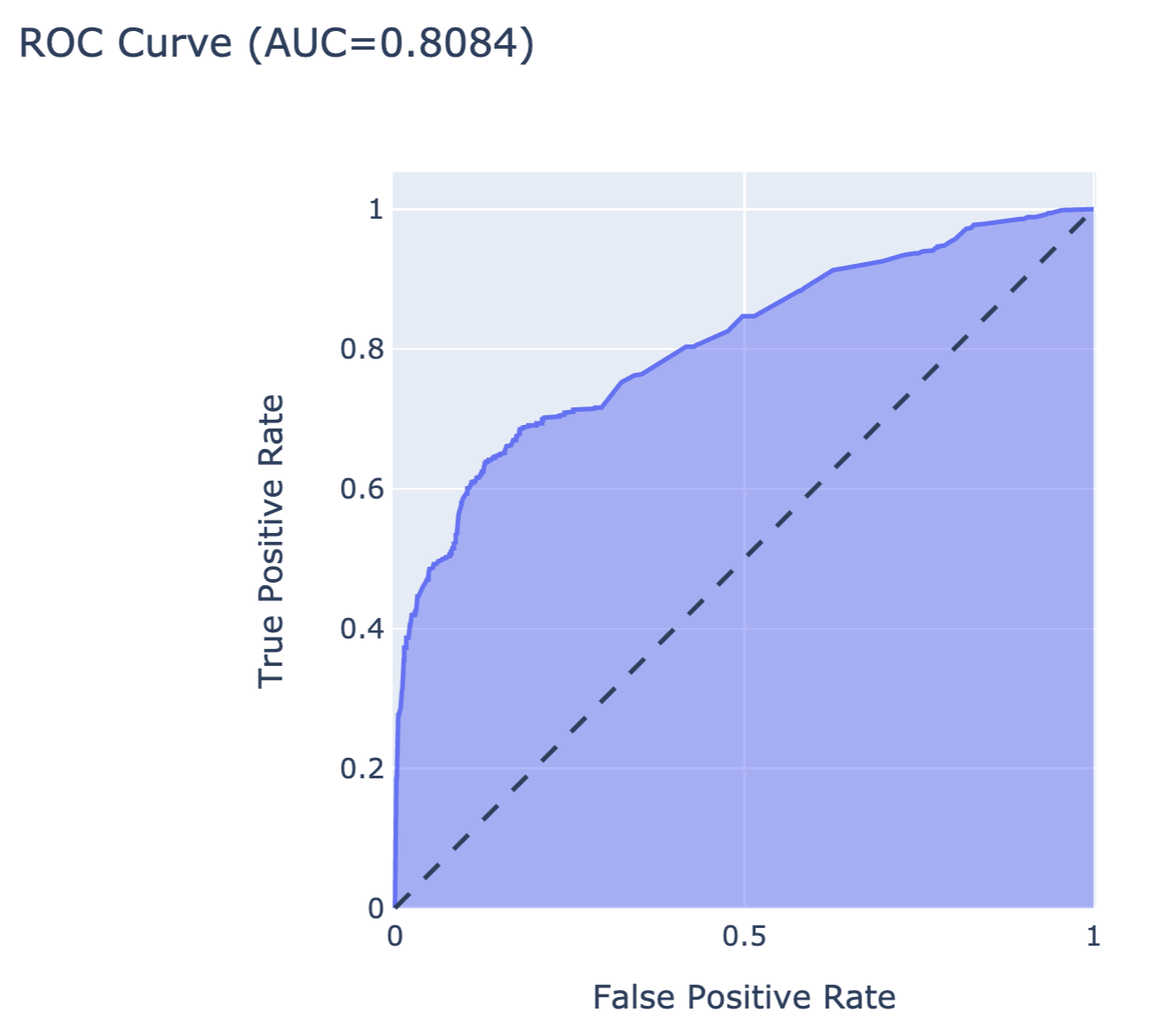
Figure 15.6: The ROC curve for the random forest model for the Titanic dataset.
The code below constructs a plot of FP and TP rates as a function of different thresholds. Figure 15.7 presents the created plot.
df = pd.DataFrame({'False Positive Rate': fpr,
'True Positive Rate': tpr }, index=thresholds)
df.index.name = "Thresholds"
df.columns.name = "Rate"
fig_thresh = px.line(df,
title='TPR and FPR at every threshold', width=700, height=500)
fig_thresh.update_yaxes(scaleanchor="x", scaleratio=1)
fig_thresh.update_xaxes(range=[0, 1], constrain='domain')
fig_thresh.show()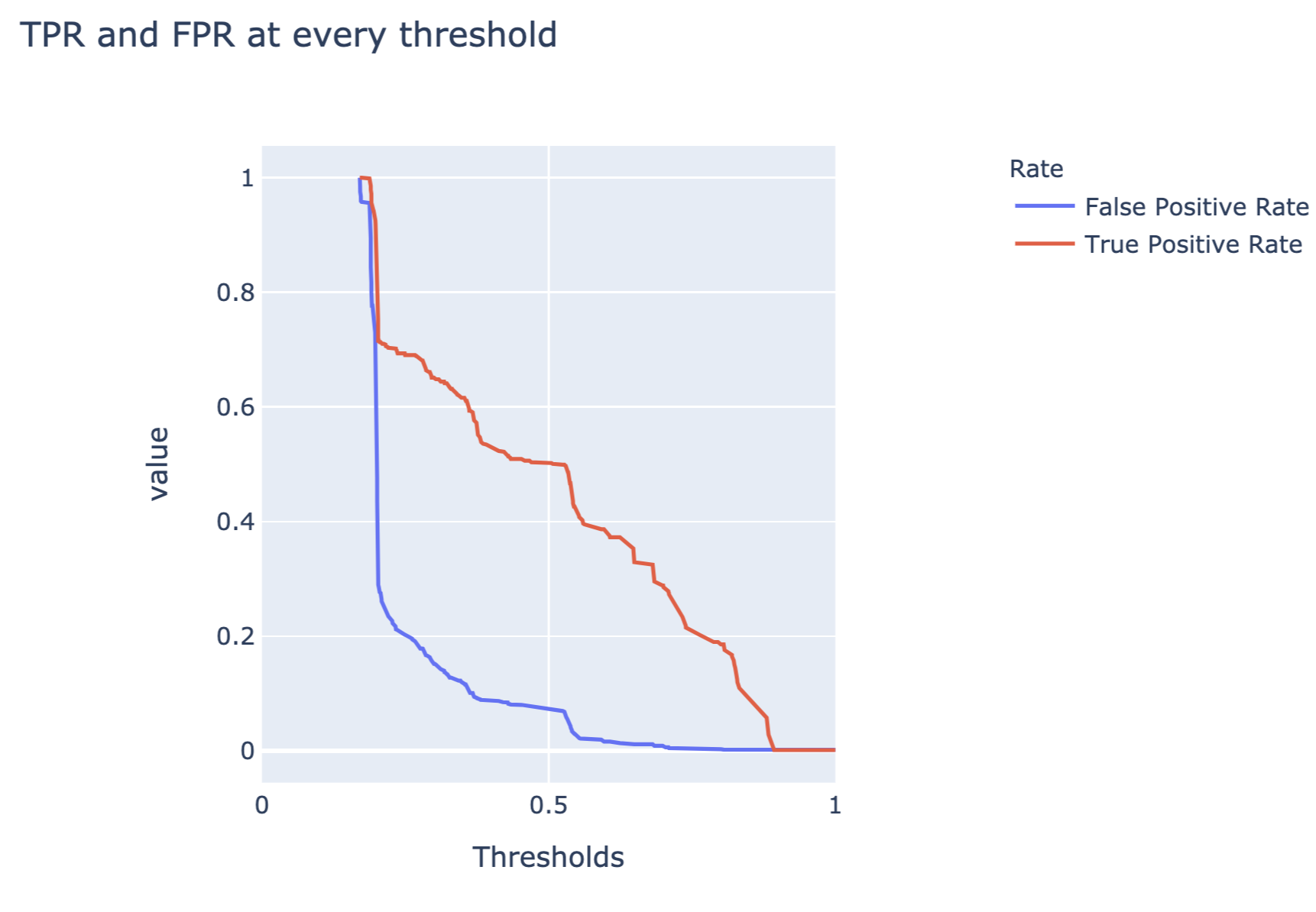
Figure 15.7: False-positive and true-positive rates as a function of threshold for the random forest model for the Titanic dataset.
References
Allison, P. 2014. “Measures of fit for logistic regression.” In Proceedings of the Sas Global Forum 2014 Conference. Cary, NC: SAS Institute Inc. http://support.sas.com/resources/papers/proceedings14/1485-2014.pdf.
Berrar, D. 2019. “Performance measures for binary classification.” In Encyclopedia of Bioinformatics and Computational Biology Volume 1, 546–60. Elsevier. https://www.sciencedirect.com/science/article/pii/B9780128096338203518.
Bischl, Bernd, Michel Lang, Lars Kotthoff, Julia Schiffner, Jakob Richter, Erich Studerus, Giuseppe Casalicchio, and Zachary M. Jones. 2016. “mlr: Machine Learning in R.” Journal of Machine Learning Research 17 (170): 1–5. http://jmlr.org/papers/v17/15-066.html.
Breiman, Leo. 2001b. “Statistical modeling: The two cultures.” Statistical Science 16 (3): 199–231. https://doi.org/10.1214/ss/1009213726.
Brentnall, A. R., and J. Cuzick. 2018. “Use of the concordance index for predictors of censored survival data.” Statistical Methods in Medical Research 27: 2359–73.
Gosiewska, Alicja, and Przemyslaw Biecek. 2018. auditor: Model Audit - Verification, Validation, and Error Analysis. https://CRAN.R-project.org/package=auditor.
Harrell, F. E. Jr. 2015. Regression Modeling Strategies (2nd Ed.). Cham, Switzerland: Springer.
Harrell, F. E. Jr., K. L. Lee, and D. B. Mark. 1996. “Multivariable prognostic models: issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors.” Statistics in Medicine 15: 361–87.
Kuhn, Max. 2008. “Building Predictive Models in R Using the Caret Package.” Journal of Statistical Software 28 (5): 1–26. https://doi.org/10.18637/jss.v028.i05.
Kuhn, Max, and Kjell Johnson. 2013. Applied Predictive Modeling. New York, NY: Springer. http://appliedpredictivemodeling.com/.
Kutner, M. H., C. J. Nachtsheim, J. Neter, and W. Li. 2005. Applied Linear Statistical Models. New York: McGraw-Hill/Irwin.
Landram, F., A. Abdullat, and V. Shah. 2005. “The coefficient of prediction for model specification.” Southwestern Economic Review 32: 149–56.
Max, Kuhn, and Hadley Wickham. 2018. Tidymodels: Easily Install and Load the ’Tidymodels’ Packages. https://CRAN.R-project.org/package=tidymodels.
Nagelkerke, N. J. D. 1991. “A note on a general definition of the coefficient of determination.” Biometrika 78: 691–92.
Rufibach, K. 2010. “Use of Brier score to assess binary predictions.” Journal of Clinical Epidemiology 63: 938–39.
Sing, T., O. Sander, N. Beerenwinkel, and T. Lengauer. 2005. “ROCR: visualizing classifier performance in R.” Bioinformatics 21 (20): 7881. http://rocr.bioinf.mpi-sb.mpg.de.
Sokolva, M., and G. Lapalme. 2009. “A systematic analysis of performance measures for classification tasks.” Information Processing and Management 45: 427–37.
Steyerberg, E. W. 2019. Clinical Prediction Models. A Practical Approach to Development, Validation, and Updating (2nd Ed.). Cham, Switzerland: Springer.
Steyerberg, E. W., A. J. Vickers, N. R. Cook, T. Gerds, M. Gonen, N. Obuchowski, M. J. Pencina, and M. W. Kattan. 2010. “Assessing the performance of prediction models: a framework for traditional and novel measures.” Epidemiology 21: 128–38.
Todeschini, Roberto. 2010. Useful and unuseful summaries of regression models. http://www.iamc-online.org/tutorials/T5_moleculardescriptors_models.pdf.
Tsoumakas, G., I. Katakis, and I. Vlahavas. 2010. “Mining multi-label data.” In Data Mining and Knowledge Discovery Handbook, 667–85. Springer, Boston, MA. https://doi.org/10.1007/978-0-387-09823-4_34.
van Houwelingen, H.C. 2000. “Validation, calibration, revision and combination of prognostic survival models.” Statistics in Medicine 19: 3401–15.