Jak zeskrobywać dane ze stron www?
Uniwersalnym i wygodnym narzędziem do pobierania danych ze stron internetowych są pakiety rvest i RSelenium. Przedstawmy je na przykładach.
Skrobanie HTMLa z użyciem pakietu rvest
Kluczowe funkcje z pakietu rvest podzielić można na trzy grupy:
read_html- wczytuje stronę internetową i tworzy drzewiastą strukturę html,html_nodes- wyszukuje węzły w drzewie pasujące do określonego wzorca (tzw. selectora),html_text,html_tag,html_attrs- funkcje wyciągające treść lub atrybuty węzłów html.
Zazwyczaj praca z pakietem rvest rozpoczyna się od wczytania strony HTML, następnie wyszukania w tej stronie interesujących fragmentów i wyłuskanie z tych fragmentów tekstu.
Zobaczmy jak te kroki wyglądają na przykładzie pobierania danych o premierach filmów w serwisie FilmWeb.
Lista premier znajduje się na stronie http://www.filmweb.pl/premiere. Aby poznać wzorce/selektory pozwalające na identyfikacje istotnej treści, najłatwiej jest zainstalować wtyczkę do przeglądarki SelectorGadget http://selectorgadget.com/. Umożliwia ona wybranie myszką interesujących elementów oraz sprawdzenie jaką postać ma selektor pasujący do zaznaczonych opcji.
Na poniższym zdjęciu przedstawiony jest przykład użycia wtyczki SelectorGadget. Zaznaczone na żółto elementy pasują do wzorca CSS .gwt-filmPage
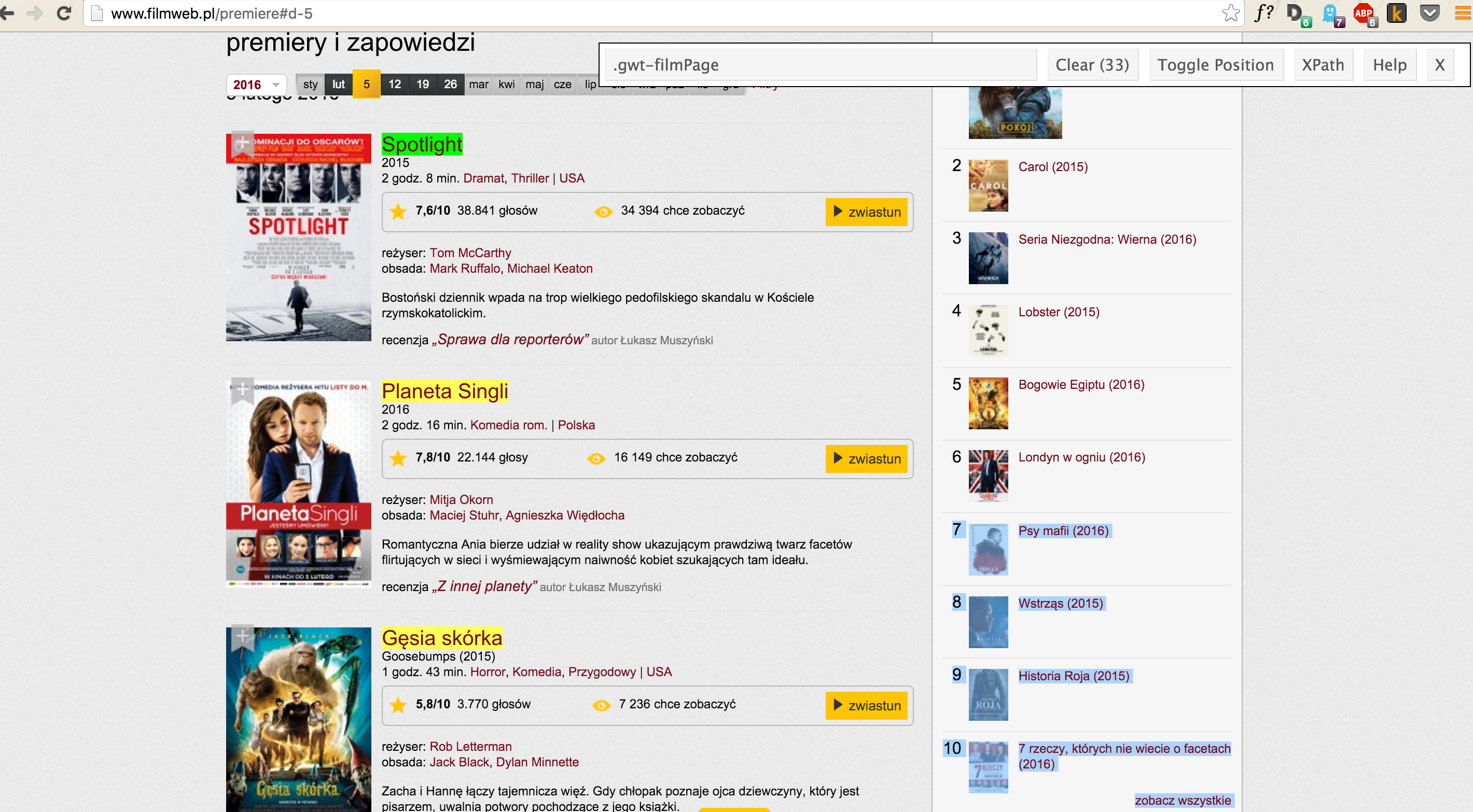
Ostatnim krokiem jest wyłuskanie danych z zaznaczonej kolekcji uchwytów. Funkcja html_text() wyciąga treść z węzłów HTML.
Poniższy przykład wybiera z serwisu FilmWeb informacje o najbliższych premierach.
library(rvest)
premiery <- read_html("http://www.filmweb.pl/premiere")
filmy <- html_nodes(premiery, ".gwt-filmPage")
html_text(filmy)
## [1] "Carol"
## [2] "Londyn w ogniu"
## [3] "Historia Roja"
## [4] "Zoolander 2 "
## [5] "Zmartwychwstały"
## [6] "Nawet góry przeminą"
## [7] "Robinson Crusoe"
## [8] "Tysiąc i jedna noc – cz. 2, opuszczony"
## [9] "Wstrząs"
## [10] "Seria Niezgodna: Wierna"
## [11] "Niewinne"
## [12] "Siostry"
## [13] "Bang Gang"
## [14] "Wszystko zostanie w rodzinie"
## [15] "El Clan"
## [16] "Zdjęcie"
## [17] "Na skrzyżowaniu wichrów"
## [18] "Tysiąc i jedna noc – cz. 3, oczarowany"
## [19] "Nieobecność"
## [20] "Psy mafii"
## [21] "Dama w vanie"
## [22] "Tata kontra tata"
## [23] "Zabójczyni"
## [24] "Powrót"
## [25] "Cały ten cukier"
## [26] "Złoty koń"
## [27] "Obsesja zemsty"
## [28] "180 sekund"
## [29] "Cuda z nieba"
Pakiet rvest pozwala też na parsowanie tabel oraz na obsługę formularzy, sesji i śledzenie linków. W poniższym przykładzie otwieramy stronę z bazy danych o filmach IMDb (Internet Movie Database) a informacjami o filmie Lego Przygoda.
Następnie trzecia tabela jest wyłuskiwana i wypisywana na ekranie.
lego_movie <- read_html("http://www.imdb.com/title/tt1490017/")
htab <- html_nodes(lego_movie, "table")[[3]]
html_table(htab)
## X1
## 1 Amazon Affiliates
## 2 Amazon Video\n Watch Movies &TV Online
## X2
## 1 <NA>
## 2 Prime Video\n Unlimited Streamingof Movies & TV
## X3
## 1 <NA>
## 2 Amazon Germany\n Buy Movies onDVD & Blu-ray
## X4
## 1 <NA>
## 2 Amazon Italy\n Buy Movies onDVD & Blu-ray
## X5
## 1 <NA>
## 2 Amazon France\n Buy Movies onDVD & Blu-ray
## X6
## 1 <NA>
## 2 Amazon India\n Buy Movie andTV Show DVDs
## X7
## 1 <NA>
## 2 DPReview\n DigitalPhotography
## X8
## 1 <NA>
## 2 Audible\n DownloadAudio Books
Skrobanie HTMLa z użyciem pakietu RSelenium
Pakiet rvest jest bardzo prosty a jednocześnie pozwala na pobranie wielu danych ze strony. Nie pozwala jednak na utrzymanie sesji i praca ze stroną tak jakby obsługiwał ją interaktywnie człowiek. Do tego typu zadań można użyć biblioteki Selenium dostępnej poprzez pakiet RSelenium.
Biblioteka Selenium po inicjacji otwiera okno przeglądarki a następnie pozwala na wykonywanie określonych operacji na tym oknie.
library(RSelenium)
checkForServer()
startServer()
przegladarka <- remoteDriver$new()
przegladarka$open()
Przykładowo funkcją navigate() możemy otworzyć w przeglądarce wskazaną stronę internetową. Funkcją findElement() możemy odwołać się do elementu na otwartej stronie internetowej. Funkcją sendKeysToElement() można zmienić wartość wskazanego elementu oraz wykonać wskazaną akcję, np. przesłać klawisz ENTER.
przegladarka$navigate("http://www.google.com")
wyszukiwarka <- przegladarka$findElement(using = "name", value = "q")
wyszukiwarka$sendKeysToElement(list("Przewodnik po pakiecie R", key="enter"))
przegladarka$goBack()
Co dalej?
- Narzędzia do zeskrobywania danych ze stron www nieustannie się rozwijają. Dobrym miejscem aby śledzić jakie są najczęstsze problemy/rozwiązania z danym pakietem jest serwis
stackoverflow.com. W przypadku pakieturvestlistę popularnych pytań znaleźć można tutaj.